![[INET 2000]](/web/20160103035927im_/http://www.isoc.org/inet2000/cdproceedings/inet00sm.gif)
![[ Up ]](/web/20160103035927im_/http://www.isoc.org/inet2000/cdproceedings/up.gif)
![[Prev]](/web/20160103035927im_/http://www.isoc.org/inet2000/cdproceedings/prev.gif)
![[Next]](/web/20160103035927im_/http://www.isoc.org/inet2000/cdproceedings/next.gif)
The impressive growth of the Internet during the past years has led to the need to overcome the limitations of the current version of the Internet Protocol (IP) in order to sustain the current growth rate for the years to come. This was at the origin of the definition of the next generation IP, called IPv6.
Nowadays the standardization work on IPv6 and related components is far enough along that vendors have already committed to a considerable number of development and testing projects. Many prototypal IPv6 implementations are already available for testing purposes on most commercial routers, UNIX workstations, and Windows PCs. Most of these implementations are being tested inside the 6bone, which is a worldwide hierarchical IPv6 network, grown on top of the Internet to assist in the evolution and deployment of IPv6. Furthermore, with the recent decision of the Internet Registries to start the allocation of official IPv6 addresses, the production usage of IPv6 is becoming closer. The 6bone is the place where Internet service providers (ISPs) looking to offer native IPv6 services are practicing.
This paper first outlines the reasons for IPv6, compared with the possibility of evolving the current version of IP (IPv4). Following a discussion of the problems associated with the transition of the current Internet to an IPv6-based network, the status of the worldwide experiments on IPv6 are presented from the point of view of CSELT, a 6bone backbone site since the beginning of 1997, which has been actively involved in assessing the 6bone experience. This analysis can provide useful feedback to evaluate the transition path.
There are many motivations behind the development of a next generation IP, standing on the weaknesses of the current IP. There is a progressive depletion of the IPv4 address space. IP host and router configuration is not an easy task. Multi-homing is complex. Renumbering is almost unaffordable, causing a continuous growth in the Internet routing tables. The user requirements for mobility, security, and QoS are great challenges for an original design that did not account for them. Suitable solutions to these problems can benefit of a new IP but are under study also as evolution and refinement of the current protocol suite or can be addressed by the improvement in the technology.
Actually, the only aspect that does not have a real alternative to IPv6 is the shortage of globally unique IP addresses. Although the theoretical number of available IPv4 addresses is 232, the practical usage of the address space is constrained by the need for flexible subnets configuration within the Internet. This fact leads us to consider the existence of a maximum efficiency for the usage of the IP address space that was discussed in RFC 1715, based on historical data for other networking protocols (SNA, DECNET, and so on). Using the IP address space with the best efficiency that any other protocol has shown, the maximum number of IP addresses that can be assigned without running in serious troubles is about 200 million.
Figure 1 shows the exponential growth of the Internet hosts since January 1993, based on DNS registration counts (see the Internet Domain Survey). These numbers represent a lower bound because not all assigned addresses have a corresponding entry in the DNS. Starting from July 1999, figure 1 depicts two estimates for the future growth: The higher one is based on all historical data (1993-1999), and the lower one is based on host counts from 1996 to 1999. From this data, it is possible to observe that the critical threshold of 200 million addresses will be reached in the time frame 2001-2003. From that time on, the IPv4 globally unique address assignment could become a real issue.
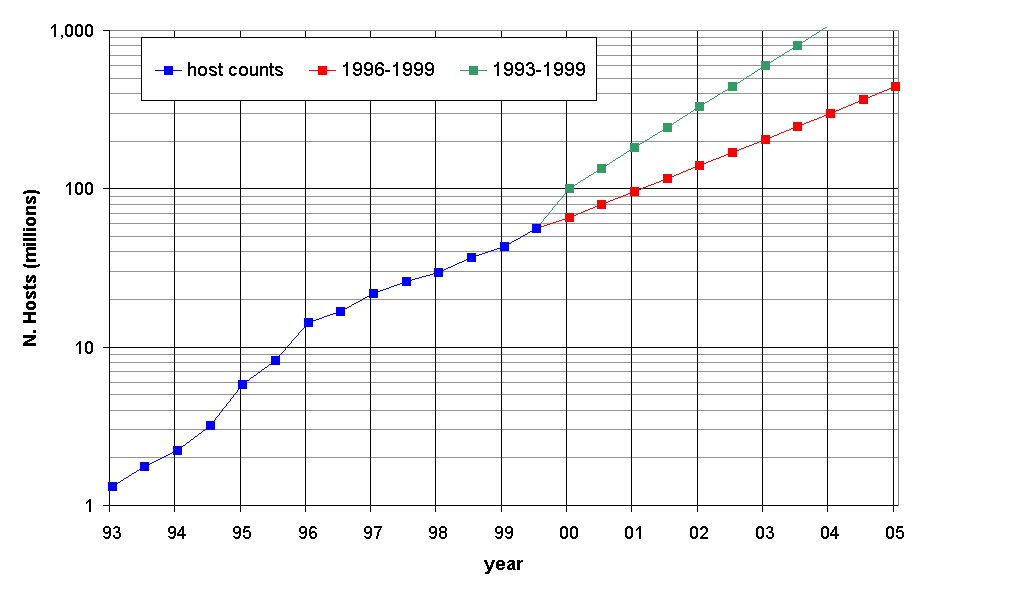
Figure 1: Growth of Internet hosts
Nevertheless, the lack of IPv4 addresses is already having an impact on the current Internet expansion within emerging countries, where requests for global and unique IPv4 addresses are hard to satisfy. Additionally, the need for IP globally unique addresses may overcome the forecasts based on the current trend if the always-on paradigm will take place, in that this will decrease significantly the benefit of IP address reuses of the mass-market users dial-up access. Both broadband wired access based on xDSL and wireless access will play a key role in this direction.
In the event that IPv6 happens, it is easy to predict that both IPv6 and IPv4 will coexist within the Internet over the medium to long term. The transition to a full IPv6 Internet will be a long process that raises several issues, most of them already under discussion within the Internet Engineering Task Force (IETF) ngtrans working group. But to have a transition, we need to face a fundamental question: Who will start? And beyond this, what is the role of the worldwide experiments that have been going on for the past three years?
Users who already have enough IPv4 addresses are not expected to deploy IPv6 in the short term due to the lack of value-added IPv6 services. For the same reason, even those who are using private IPv4 addresses together with Network Address Translators (NATs) or proxies are not likely to deploy IPv6.
On the other hand, new users may think of deploying IPv6 now as a future proof opportunity. These users have basically two technical alternatives: They can deploy a dual-stack network or an IPv6-only network. Deploying a dual-stack network has the great advantage of allowing easy transition, assuring full interoperability with the traditional IPv4 Internet. However, it increases network complexity, and the user has to manage a double (IPv4/IPv6) routing infrastructure. On the other hand, a new user could deploy an IPv6-only network (see figure 2) and Network Address Translators-Protocol Translators (NAT-PTs) instead of a private IPv4 network with NAT. This is because deploying an IPv6-only network and NAT-PT is approximately as complex as deploying a private IPv4 network with NAT, and it has the advantage that the usage of NAT-PT will be a temporary patch waiting for a future IPv6 Internet.

Figure 2: An example of IPv6 only site
The user-driven transition scenario based on the IPv6-only approach might really become the first step towards the worldwide adoption of IPv6. New customers could already take advantage of it even though no IPv6 killer applications are yet on the horizon. Nevertheless, in order to undertake this evolutionary path, it is fundamental to be able to deliver even on an IPv6-only infrastructure most of the application services that are available today with IPv4. These include at least the most common Intranet and Internet services, such as DNS, WWW, e-mail, print services, file transfer, and remote access.
Unfortunately, the number of IPv6 applications currently available is very limited and is certainly not enough for the deployment of an IPv6-only network in a real production environment. This conclusion is confirmed by the results of a recent survey (see table 1) that was carried out at CSELT to classify the application-level software available on some of the most commonly used IPv6 platforms (FreeBSD Inria, FreeBSD KAME, Linux, SUN Solaris and Windows NT/2000 from Microsoft Research). This report may not be exhaustive and its validity is at January 2000, but it suggests that any network administrator willing to deploy an IPv6-only Intranet would run into serious problems just trying to provide some very basic network services to the users.
The first strong issue is represented by the fact that several platforms are still lacking support for IPv6 transport of DNS messages on the client side. This in principle obliges network administrators to deploy a dual-stack network instead of an IPv6-only one just to relay on IPv4 for IPv6 name resolution. Further problems arise with respect to the Web services, given that some of the most common Web browsers neither now nor in the future announce updates support IPv6. Almost the same story applies to other basic application services, such as e-mail exchange and remote printing, for which there is still very little support, especially on the client side. For example, among the IPv6 platforms considered in this survey, only the IPv6 stack for FreeBSD developed by the KAME consortium is known to include an IPv6-capable POP client usable to fetch mail from a distant mail server.
The problems coming from the absence of a complete set of IPv6 applications could be partially solved by placing on every host a Bump-in-the-Stack (BIS) module capable of translating IPv4 into IPv6 and vice versa. This mechanism allows IPv6 hosts to communicate over an IPv6-only network even using existing IPv4 applications. It must be noted anyway that this approach has the same strong limitations of a NAT box (RFC 2663). It is therefore expected that a network administrator will hardly accept the migration to IPv6 if that will imply the burden of placing such a functionality on every host.
Another nontrivial issue that has not yet been completely addressed is the lack of network management features on most commercial IPv6 routers. In most cases, the IPv6 MIBs, although already specified by the IETF, are not implemented at all and the SNMP protocol is not supported, which makes almost impossible the deployment of any production IPv6 service.
Table 1: Software availability as of January 2000
| Service | Protocol | Client | Server |
|---|---|---|---|
| DNS | DNS | Resolver with IPv4 transport (Linux, Solaris 7, Windows NT/2000)
Resolver with IPv6 transport (FreeBSD KAME) |
Bind and Newbie with
IPv6 transport (FreeBSD Inria and KAME)
Bind with IPv4 transport (Linux, Solaris 7) |
| WWW | HTTP | Internet Explorer
(Windows NT/2000)
mMosaic (Solaris 7) Mozilla (FreeBSD KAME) Lynx (FreeBSD KAME) MMM (FreeBSD Inria) Chimera (Linux) |
Apache (Linux, FreeBSD Inria and KAME)
NCSA HTTP Server (Solaris 7) Fnord! (Windows NT/2000) Inframail (Windows NT/2000) |
| Print services | Lpr (FreeBSD Inria and KAME) | Lpd (FreeBSD Inria and KAME) | |
| POP, SMTP, IMAP | Sendmail (all Unix platforms)
qmail (FreeBSD KAME) Fetchmail (FreeBSD KAME) |
Sendmail (FreeBSD Inria and KAME, Linux)
Inframail (Windows NT/2000) Trumpet Winsock/Fanfare (Windows 3.11/95/NT) |
|
| File transfer | ftp | standard ftp client with textual interface (all UNIX platforms)
ncftp (FreeBSD KAME, Linux, Windows NT/2000) |
ftpd (all UNIX platforms)
Inframail (Windows NT) Trumpet Winsock/Fanfare (Windows 3.11/95/NT) |
| Remote access | telnet | standard telnet client with textual interface (all Unix platforms) | telnetd (all Unix platforms)
Trumpet Winsock/Fanfare (Windows 3.11/95/NT) |
| Network management | SNMP
IPv6 MIBs |
Some IPv6 MIBs (FreeBSD KAME) | Some IPv6 MIBs (FreeBSD KAME) |
| File servers | NFS (based on RPC and XDR) | mount_nfs (FreeBSD Inria) | nfsd (FreeBSD Inria) |
Service providers may have different attitudes to IPv6. New providers aiming at innovative service offerings targeted to build their own market share may be interested in pushing IPv6 as an enabling technology. This could be the case of mobile telephone operators willing to enter the Internet arena. They may bet on IPv6 as a way to address their need for a huge amount of globally unique IP addresses or as a new technology that can allow them in shorter term to close the gap with the traditional ISPs, in terms of expertise and global knowledge. But in general, the intentions of the newcomers are still at the level of future business plans, with all the related uncertainties.
Traditional ISPs have their own business focused on IPv4, and they are often tempted to wait for a significant user demand before offering IPv6 services. In spite of that fact, several ISPs already started to care about IPv6, in order to promote their brands of innovative ISPs, to have new elements for the design of their next generation networks and to train at least some Network Operation Centre (NOC) staff people. A number of ISPs are already involved in the international experimentation of IPv6 carried out on the 6bone. Their role has been important in building and operating a backbone for IPv6 together with several Research and Educational Networks and some Internet Exchanges. Most of them have contributed in the setup of the first native IPv6 links on the wide area. They have asked and obtained by IANA the possibility to apply for official IPv6 addresses to be used for commercial purposes: About 20 ISPs in North America, Europe, and Asia Pacific already have their own IPv6 address spaces, planning the first service field trial for IPv6.
The 6bone is an experimental IPv6 network layered on top of portions of the physical IPv4-based Internet. The 6bone supports routing of IPv6 packets within an environment where this function is not yet integrated into the production routers. The network is made up of islands that can directly support IPv6 packets, linked mainly by virtual point-to-point links called "tunnels."
The idea to set up an experimental IPv6 backbone over the Internet was the result of a spontaneous initiative of several research institutes involved in the experimentation of the first implementations of the IPv6 protocol. The network became a reality in March 1996, with the establishment of the first tunnels between the IPv6 laboratories of G6 (France), UNI-C (Denmark), and WIDE (Japan).
The 6bone is the place where the most interesting geographical experimentation on the IPv6 protocol is currently taking place. The experimental activities carried out inside the 6bone are coordinated by the IETF in order to provide feedback to various IETF IPv6-related activities and to IPv6 product developers based on testbed experience.
The 6bone is structured as a three-level hierarchical network (figure 3) with backbone nodes, transit nodes, and leaf nodes. The 6bone backbone is made of a mesh of IPv6 over IPv4 tunnels (and some direct links) interconnecting backbone nodes only. IPv6 routing inside the backbone is based on the BGP4+ protocol. Transit nodes connect to one or more backbone nodes and provide transit service for leaf sites. Routing outside the backbone is mainly static, but the number of nonbackbone sites making use of IPv6 routing protocols, such as RIPng and BGP4+, is rapidly growing.

Figure 3: Logical structure of the 6bone network
IPv6 addressing inside the 6bone is based on the new IPv6 Aggregatable Global Unicast Address Format (RFC 2374); it matches the hierarchical topology described above. Backbone nodes play the role of experimental Top-Level Aggregators (TLAs). They are responsible for assigning IPv6 addresses to nonbackbone sites in such a way as to establish an addressing hierarchy capable of enforcing aggregation of routing information.
The whole 6bone is identified by the IPv6 prefix 3ffe::/16. Every backbone node is assigned a 24- or 28-bit long prefix [pseudo Top-Level Aggregators (pTLA) prefix] identifying an IPv6 addressing space, which must be administered following all the rules defined for the TLAs. According to this model, every pTLA plays the role of experimental top-level ISP and has to assign chunks of its addressing space to directly connected transit and leaf sites without breaking aggregation inside the 6bone backbone.
Since its creation in 1996, the 6bone has been steadily growing in the number of connected sites (see figure 4). In July 1997, the network encompassed about 150 sites; in January 2000, more than 500 sites distributed in 42 countries all over the world were officially registered in the 6bone registry database. Over the same period of time, the number of 6bone backbone sites (i.e., assigned pTLAs) has increased from 36 to 67.


Figure 4: Growth of the 6bone over the last three years (source: 6bone
registry)
The CSELT's IPv6 laboratory joined the 6bone initiative at the end of 1996 and became a backbone site immediately after the hierarchical reorganization of the network, which took place a few months later. The CSELT's IPv6 connectivity within the 6bone backbone is guaranteed by a large number of BGP4+ tunnels established over the Internet (see figure 5). In order to achieve good performances, the peering points were selected among the backbone sites that were reachable from CSELT through the standard IPv4 Internet with the lowest end-to-end packet loss and latency.

Figure 5: CSELT's backbone tunnels
The CSELT's IPv6 network (see figure 6) has been designed to separate as much as possible the IPv6 traffic exchanged among internal IPv6 users from the external IPv6 traffic in transit through the CSELT's backbone node. For this reason, the CSELT's internal IPv6 hosts and servers (WWW, ftp, DNS, and so on) are located in a dual-stack corporate backbone. It is connected through a dedicated gateway to the network, which hosts the border routers used to access the backbone peers as well as the CSELT's Italian leaves. This network structure also provides a single point of access to the CSELT's experimental IPv6 corporate backbone. This is quite useful for trying out most of the transition mechanisms (NAT-PT, application level gateways, and so on) that are being designed to support the IPv6-only transition scenario described above.
The IPv6 routing within the CSELT's IPv6 network is still based on RIPng (RFC 2080), waiting for stable implementations of OSPFv6 (RFC 2740) on commercial IPv6 routers. The reliability of the 6bone backbone access is guaranteed by the fact that two BGP4+ routers are used for that purpose, each one terminating about one half of the CSELT's backbone tunnels.

Figure 6: Structure of the CSELT's IPv6 network
CSELT has been actively involved in the development of a set of methodologies and tools to monitor the performance of BGP4+ routing within the network. The most relevant result of this work has been the development of a software package called ASpath-tree, which is freely available and can be used by any site connected to the 6bone BGP4+ cloud to collect a wide range of BGP4+ operational reports. As a basic feature, ASpath-tree makes a snapshot of the BGP4+ routing table of a backbone IPv6 router and generates a set of Hypertext Markup Language (HTML) pages. This provides a graphical view of the Autonomous System (AS) paths towards the other sites and highlights the incidental presence of invalid or unaggregated (i.e., longer than the related pTLA delegation) route entries. Additionally, when ASpath-tree is executed periodically, it uses data from the snapshots of the past 24 hours to perform a rough routing stability analysis.
At CSELT, ASpath-tree is used to take regular snapshots (every 5 min) of the BGP4+ routing table from one of the IPv6 border routers used to access the 6bone backbone. Moreover, a selected set of data is stored in a local archive to be available for further off-line elaboration. This data include
This procedure has been in place since September 1998. The huge amount of data collected so far have been used to study how the BGP4+ routing behavior within the 6bone has evolved during the last year and a half, in terms of number of prefixes advertised within the BGP4+ cloud, route unavailability, and routing unstability.
The availability of a reliable, well-designed interdomain routing system is obviously the core component of the Internet and, in general, of any IP-based wide area network. For this reason, most of the work carried out within the 6bone over the last years has been focused on the experimentation of the BGP4+ protocol among the participating sites. This activity has provided precious inputs both to the router manufacturers, who have fixed and improved their implementations, and the network administrators, who have gained experience with the new routing protocol and have learned how to achieve an optimal tuning of its capabilities.
The number of prefixes advertised to CSELT during the past year and a half is plotted in figure 7. The graph shows both the total number of IPv6 prefixes and the number of pTLA prefixes. In theory, the two numbers should have been equal; in practice, the difference between the two is the sum of the following contributions:
Figure 7 shows that since September 1998, the number of pTLA prefixes advertised within the BGP4+ cloud has grown from 35 up to a maximum of 58, which was reached at the end of 1999. This immediately highlights that not all the assigned pTLAs (66 plus CSELT at the beginning of year 2000) are actively participating into the BGP4+ cloud.
Similarly, the total number of IPv6 prefixes announced within the BGP4+ cloud has varied around an average of about 80 in the time frame from September 1998 to July 1999. Later on, the size of the BGP4+ routing tables has slightly increased so that, apart from a major prefix proliferation that took place at the end of October 1999 due to some bogus BGP4+ gateways [1], it is now oscillating around an average of 100 IPv6 prefixes. This growth is mainly due to the fact that in August 1999, the Internet Registries began to assign the first production IPv6 prefixes to the requesting organizations (the very first one was assigned by ARIN to ESnet in August 9, 1999). They therefore started to announce in the BGP4+ cloud also these newly assigned IPv6 prefixes together with their experimental pTLA delegations.
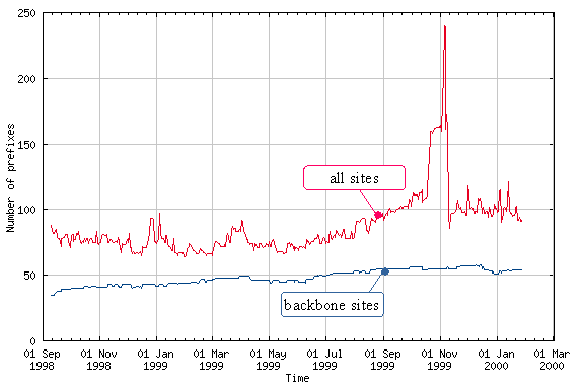
Figure 7: Number of prefixes advertised in the BGP4+ cloud
Since November 1999, there have been just a few invalid prefixes and about 13 IANA routes (including the one used for the 6to4 experimentation) permanently announced within the 6bone BGP4+ cloud. Meanwhile, the number of unaggregated prefixes has varied between 20 and 30. These unaggregated routes are generated both by (1) the pTLAs that are not filtering out in the proper way the IPv6 routes towards their single-homed customers and (2) the pTLAs that are supporting multi-homed customers relaying on a single IPv6 prefix.
Although it is certainly possible and desirable to further improve the level of prefix aggregation within the 6bone (e.g., handling multi-homing in the right way), it is worthwhile to note that the number of unaggregated routes advertised within the BGP4+ cloud is already quite small and has been little affected by the fact that the total number of sites connected to the 6bone has grown from 300 to 500 in the period from September 1998 to January 2000. This fact looks very good if compared with the poor prefix aggregation of the current Internet.
The route unavailability towards a given destination over a given time frame (e.g., one day) as it is seen from a well-defined probing site can be defined in general as the time share (in percent) during which no valid IPv6 routes towards that destination were available on the probing router. This performance parameter, which can be used within any IP network regardless of the employed routing protocols, provides a strong indication about the reliability of the communications; the higher values of unavailability stand for longer periods of destination unreachability due to the lack of the relevant routing information. Additionally, the route availability may be averaged on a number of sites, giving an indication about the reliability of a portion of a network.
Provided that the 6bone network has a hierarchical structure based on the backbone sites, the BGP4+ route unavailability towards every known pTLA is representative of the route unavailability towards the whole network. It is therefore a performance parameter that is certainly worth monitoring. At CSELT this is done using the data collected with ASpath-tree. It is important to note that the overall 6bone BGP4+ route unavailability include at least four main components:
The first three components are intrinsic to the experimental nature of 6bone, so that only the fourth really provides an indication about the maturity of the currently available IPv6 technology. Unfortunately, comparing the routing information with the registry information, only the very first contribution can be easily separated from the others.
Figure 8 shows how the overall BGP4+ route unavailability within the 6bone has changed since September 1998, according to the CSELT's measures. Both the unavailability averaged over the whole backbone (higher line) and the one calculated considering only the active pTLAs are plotted: The gap between the two lines is exactly the percentage of officially designated, but not yet active, pTLAs.
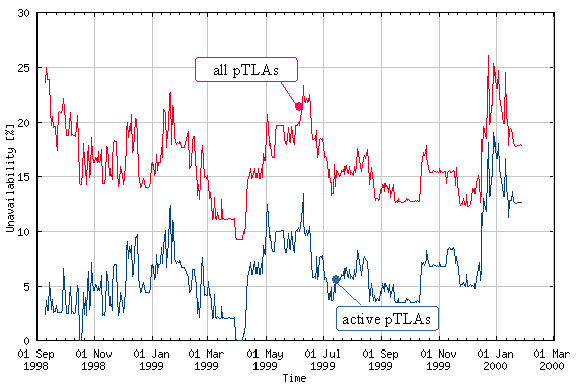
Figure 8: Overall BGP4+ route unavailability within the 6bone
The values of route unavailability are quite high if compared with those of any production network (where normally the route unavailability is very close to 0 percent) but still impacted from the experimental nature of 6bone. Trying to filter further the "experimental noise," it is worthwhile to look at the route unavailability of each individual pTLA. Figure 9 shows the upper bound of the route unavailability for 80 percent of the total number of backbone sites over time. This result demonstrates that most 6bone pTLAs have always been reachable within the BGP4+ cloud. Therefore, the high values of overall BGP4+ route unavailability in figure 8 are due to the unreliability of a few pTLAs rather than to the unreliability of the whole backbone. This is a very positive result for the 6bone operations, which confirms the good level of maturity reached by the currently available IPv6 technology.
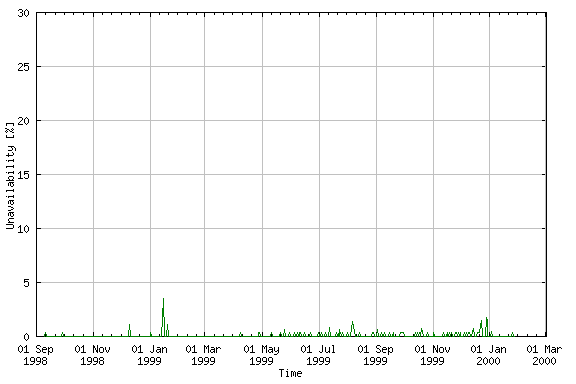
Fig. 9: BGP4+ route unavailability (upper bound for 80% of pTLAs)
The routing unstability can be defined in general as the frequency of changes in the routing paths followed by the packets in transit among communicating sites. The routing unstability should be kept as low as possible because high values of this parameter may cause a high router processing load as well as a waste of bandwidth due to the excessive rate of routing update signaling messages exchanged among neighboring routers.
At CSELT, the routing unstability is measured by counting day by day the number of route changes for every pTLA, using the data collected with ASpath-tree. The first of the two charts presented in figure 10 shows the BGP4+ routing unstability of the most stable and of the most unstable 6bone pTLA, respectively. It is easy to note that at any time the BGP4+ routing unstability of the most stable pTLA is very close to 0 percent, which means that the correspondent AS path rarely changes during the day. On the contrary, the BGP4+ routing unstability of the most unstable pTLA commonly reaches very high values (up to 90 percent), which means that the correspondent AS path keeps changing and the related BGP4+ signaling traffic is quite high.
Fortunately, this worst case behavior applies just to a very small number of the 6bone pTLAs. In fact, trying again to filter the "experimental noise" of the 6bone, the second chart in figure 10 shows the upper bound of the route unstability for 80 percent of the total number of backbone sites over the time. This value normally has been lower than 5 percent, confirming the good level of maturity reached by the currently available IPv6 implementations.
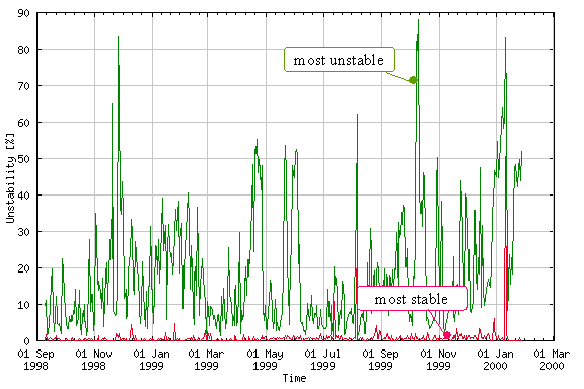

Figure 10: Unstability min, max and at 80 percent within the BGP4+
cloud
After years of work within the IETF, the standardization of IPv6 and related components is coming to an end. Although at the same time the existing IPv4-based technology has been enhanced to partially cope with the problem of IP addressing space depletion as well as with the growing demand for new services like security, mobility, and QoS, this has not removed but just delayed the need for a new network protocol as a long-term solution. In fact, it is quite clear that no low-cost IPv4 patches will ever be able to guarantee the end-to-end network transparency and the huge amount of globally unique IP addresses required by the Internet evolution (e.g., the future xDSL or wireless data services based on the always-on paradigm). This is a very strong reason for deploying IPv6 within the Internet.
This is why most of the major Internet ISPs are already looking with great attention at IPv6 and have been involved in the experimentation of the new protocol within the 6bone for years now. Their contribution, together with the increasing effort coming from manufacturers, universities, and research centers from all over the world, is making the experimental IPv6 Internet grow fast. Nowadays, more than an environment to test IPv6 implementations, debug vendor equipment, and practice with it, the 6bone and the ISP trials look like the down of the transition process. For this reason, it is time to start IPv6 activities, even for those ISPs who have not been involved up to now.
The results of the 6bone monitoring effort carried out by CSELT since September 1998 confirm that BGP4+ routing within the 6bone backbone has become highly reliable, both with respect to stability and route availability. This in turn highlights the good level of maturity reached by the currently available IPv6 technology and confirms that it could be successfully employed even in a production environment.
Nevertheless, it is important to note that some other issues still need to be solved before a large-scale deployment of IPv6 within the Internet can take place. The 6bone experience shows that multi-homing is still a problem, given that many of the unaggregated IPv6 prefixes advertised within the BGP4+ cloud are due to lack of an alternative to the current inefficient IPv4 practice. Moreover, the renumbering issue is worth further investigation and standardization effort.
Finally, to make IPv6 attractive to users -- and particularly to new users who may foster the worldwide adoption of IPv6 by choosing the IPv6 only-transition scenario -- a suitable range of IPv6 applications must be available, starting from the basic services typical of the present Internet and Intranet environments. The present lack of such application services clearly indicates that the application developers and manufacturers will have a key role in leading the transition process and making the new IPv6 Internet really happen.
[1] This major failure was called the "zombie routes phenomenon" and was due to some bogus BGP4+ gateways that never withdrew the BGP4+ routes learned from the peers, even if they were already expired. The identification and fix of this bug took several days; during that period the total number of prefixes going around within the BGP4+ cloud reached its maximum at 240.